Near:
About
Near is an experimental project which questions how tightly the view presented by a file explorer should be coupled with the structure of the underlying file system.
Classically file explorers have been a one-to-one presentation of the file tree of the system. We have been exploring transformations which can be applied to the tree in order to be more useful when searching, organising and working with files, without affecting the file structure on disk. We feel this could be beneficial for three reasons:
- compatibility: Many tools store fixed paths, which may become tedious to update when rearranging files. Decoupling presentation and storages allows you to make changes to the organisation of your files without affecting programs which depend on them.
- dynamicity: By allowing a user to rapidly switch between views of the same files, a more appropriate organisational structure can be selected for a given task.
- complexity: Modern file systems contain lots of complexity, which is passed on to applications interacting with the file system. If the file manager does more, the file system has to do less. This in turn would allow other applications to be developed more easily as the difficulties of working with a complex file system are no longer existent.
The Past
Our initial experiments were based around basic transformations which could be composed to form a virtual view of the file tree.
The first prototype proposed the primitives flatten, group and slice. Flatten virtually moves a file into its parent directory, allowing the user to compress deeply nested file hierarchies. Conversely, group allows files to be combined into effectively a virtual directory. Slice constrains the set of viewed files to the subset matching the search criteria.
The prototype's own source files 'sliced' based on tag metadata stored by the file manager.
This design had some significant problems. Flatten was unnecessarily constrained to moving files into only their parent directory. Group became problematic as a group had to effectively be 'mounted' into the filesystem to be visible, emulating many of the complexities found in filesystems which we were trying to avoid.
The next prototype discarded group and replaced the flatten operation with the more powerful rebase, allowing any file to be virtually moved into any parent directory.
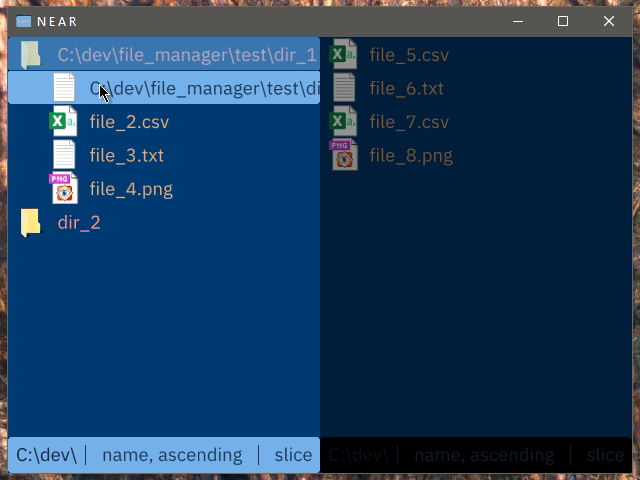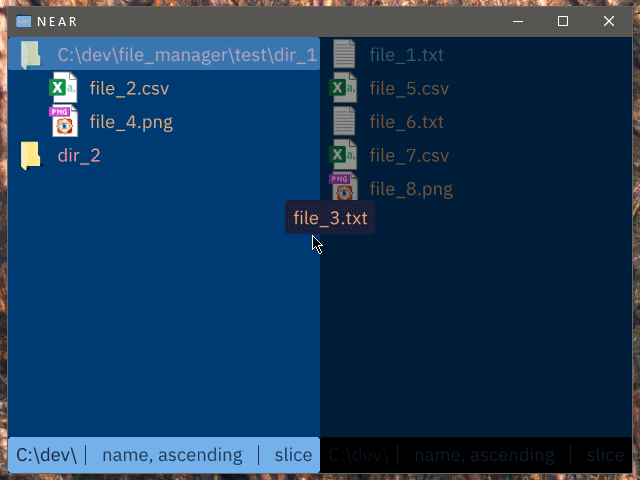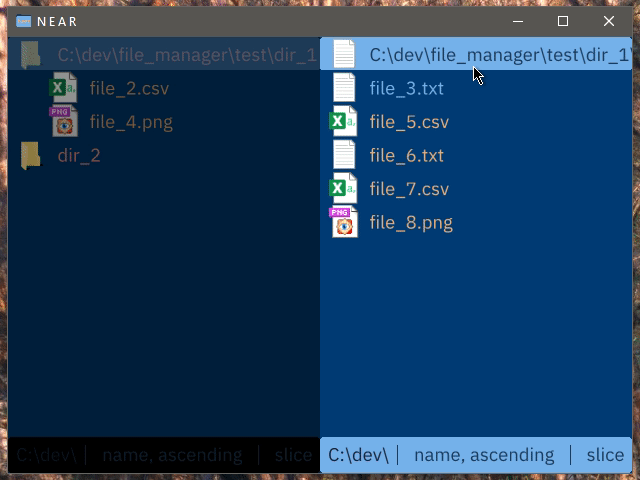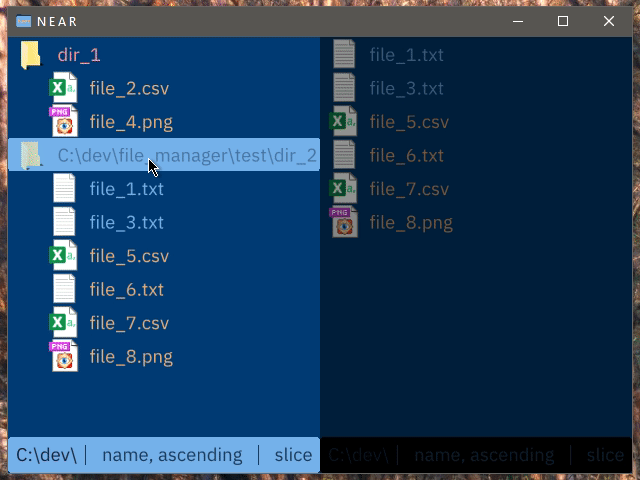
Holding a modifier key and dragging virtually rebases instead of performing a hard move
The mapping filename → virtual filename encoded by rebase operations provided a simpler, clearer conceptual model and was flexible enough to describe nearly any transformation to the tree structure. However, manually moving files one by one (or even with multiple selection) was not a useful interface. In addition, many degenerate cases (e.g., rebase into a folder, delete folder) were possible, resulting in many bugs.
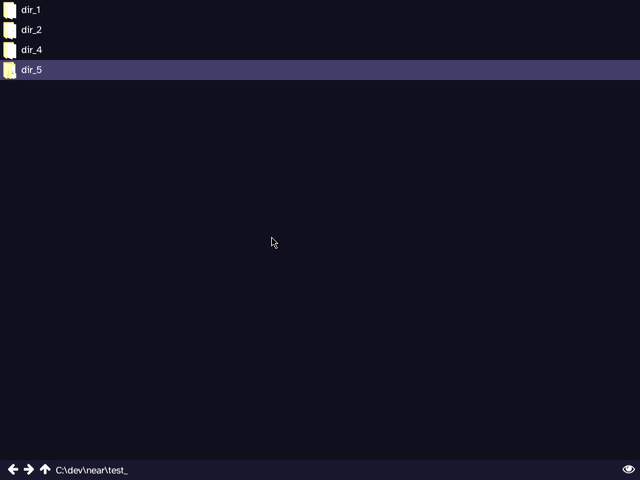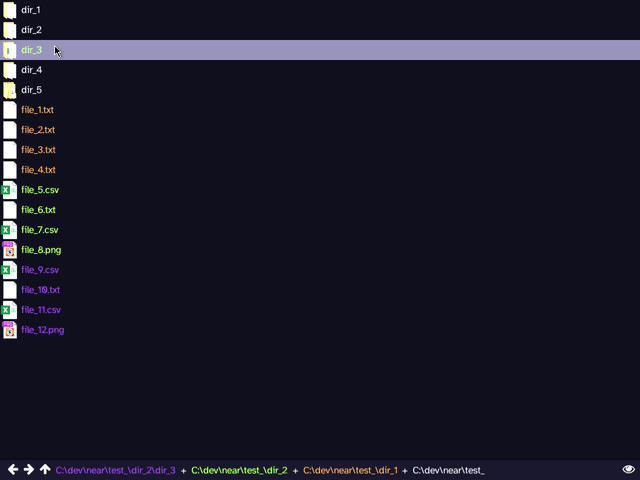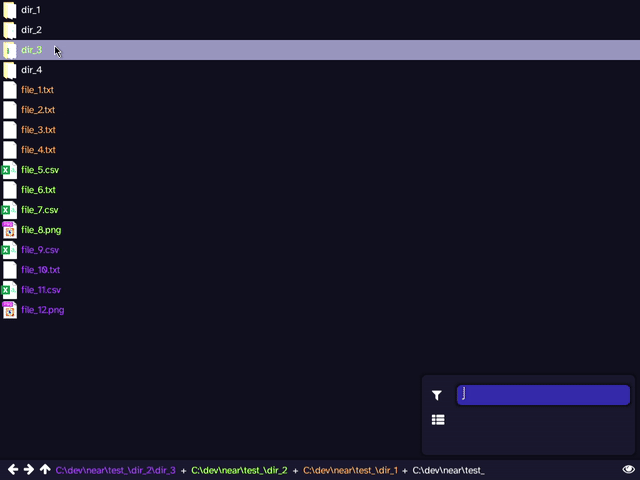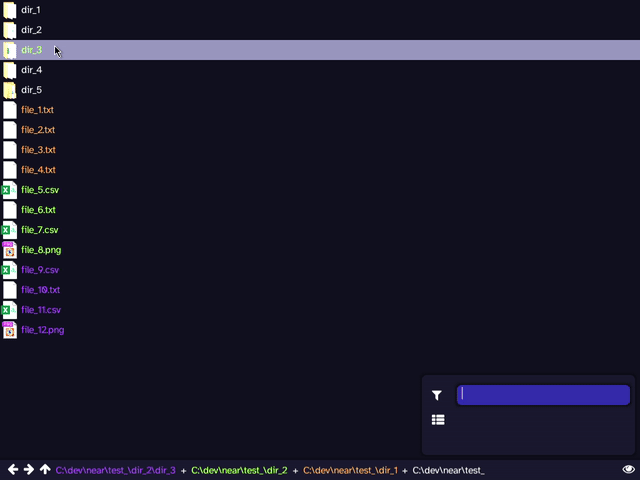
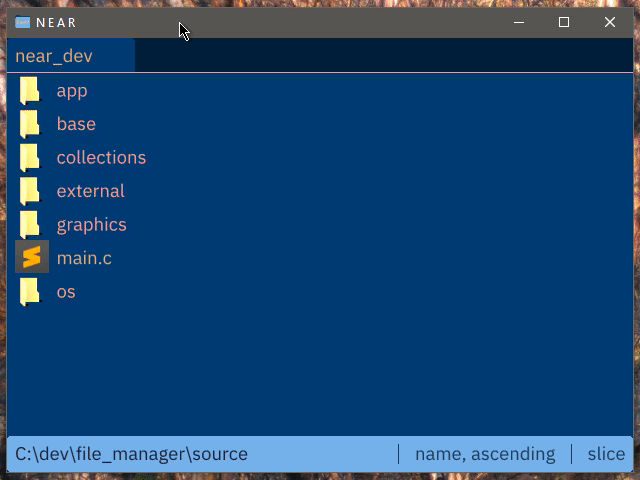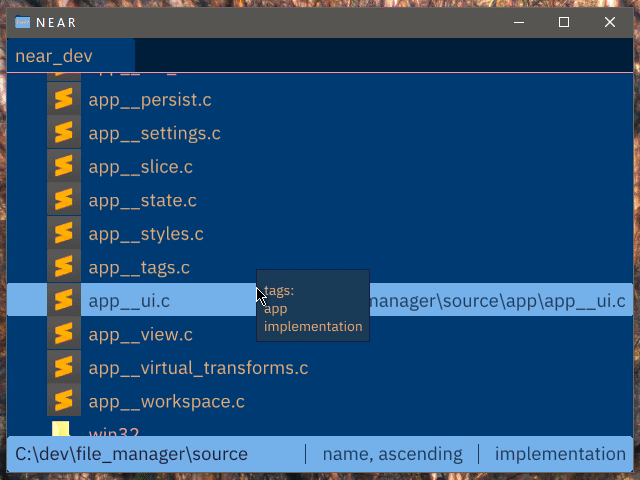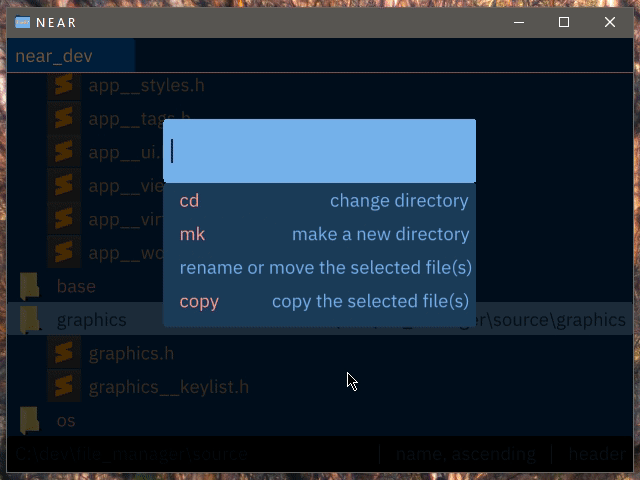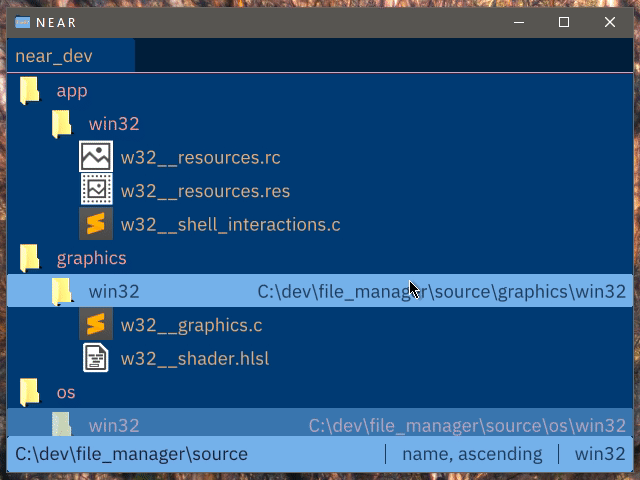
The most recent prototype simplified things further, discarding all together the idea of applying a 'virtual transformation' to a file. Instead, it is based around the idea of viewing a union of directories, rather than a single directory at a time, as in a traditional file manager. This combined with filtering ('slicing'), provided the first glimpse of something that may be usable. Although objectively less powerful, it provides better ergonomics and reduces the possibility of confusing, useless, or all-together broken cases. Many familiar commands from traditional file managers have close analogies within this model: 'back' and 'forward' work identically, 'up' can be applied elementwise to the list of directories.
Clicking while holding a modifier key adds the directory to the list of viewed directories, instead of entering into it. Colour coding is used to make files from different directories easily visually distinguishable.
The Future
Our research so far seems to have left us with more questions than answers. Here are some of the things we will be thinking about next.
All of the prototypes so far have been based around relatively thin layers on top of current file organisation techniques. This has value: although we believe there are benefits to decoupling storage from presentation, it is dangerous to discard the storage mechanism as a mere "implementation detail" as it is sure to have influence on nearly all operations working with files. If complete control over the filesystem was viable, what other presentations would be useful or viable?
How would a filesystem be designed with a file manager of this kind in mind? Which features belong in the lowest level, and which should be implemented higher up the stack?
Examples such as voidtools' Everything show how powerful searching a large set of files with instant feedback can be. What is the best format for providing more complex queries? How can queries compose? How do you design an interface for sufficiently advanced queries that doesn't devolve to a scripting language?